Predicting University Enrollments with Machine Learning
View project on GitHub
So far, the procedure for university enrollments it has been done manually. In addition, it has always required a great effort and experience on the part of the team that manages them. We are facing a complex problem, that is, if we wanted to automate this procedure, we could not apply a traditional approach nor any generic rule or algorithm to determine whether or not a student will enroll because of the behavior of each student is quite unpredictable. For this reason, it is proposed to apply Machine Learning with the purpose of generating and analyzing various predictive models based on the previous academic history of all students.
On the following table we can see the simplest form of data that the university collects, in this case, without taking into account the personal information of the students (anonymized) such as university entrance grade, scholarship and so on:
id | student_id | course_id | acronym | year | semester | grade |
|---|---|---|---|---|---|---|
| 0 | 193b01116d | 330212 | MBE | 2010 | 1 | 7.4 |
| 1 | 193b01116d | 330213 | F | 2010 | 1 | 6.2 |
| 2 | 193b01116d | 330214 | I | 2010 | 1 | 10.0 |
| 3 | 193b01116d | 330215 | ISD | 2010 | 1 | 9.0 |
| ... | ... | ... | ... | ... | ... | ... |
| 11122 | 283732537e | 330212 | MBE | 2020 | 1 | 9.2 |
| 11123 | 283732537e | 330213 | F | 2020 | 1 | 7.9 |
| 11124 | 283732537e | 330214 | I | 2020 | 1 | 9.0 |
| 11125 | 283732537e | 330215 | ISD | 2020 | 1 | 7.0 |
Dataset
We start with a historical record containing the files of all students, following the format of the previous Table. Then, we aim to define possible transformations, that is, two datasets with the purpose of building two sets of data for training the models. For this reason, we define a series of modules to facilitate the treatment and manipulation of the data, specifically:
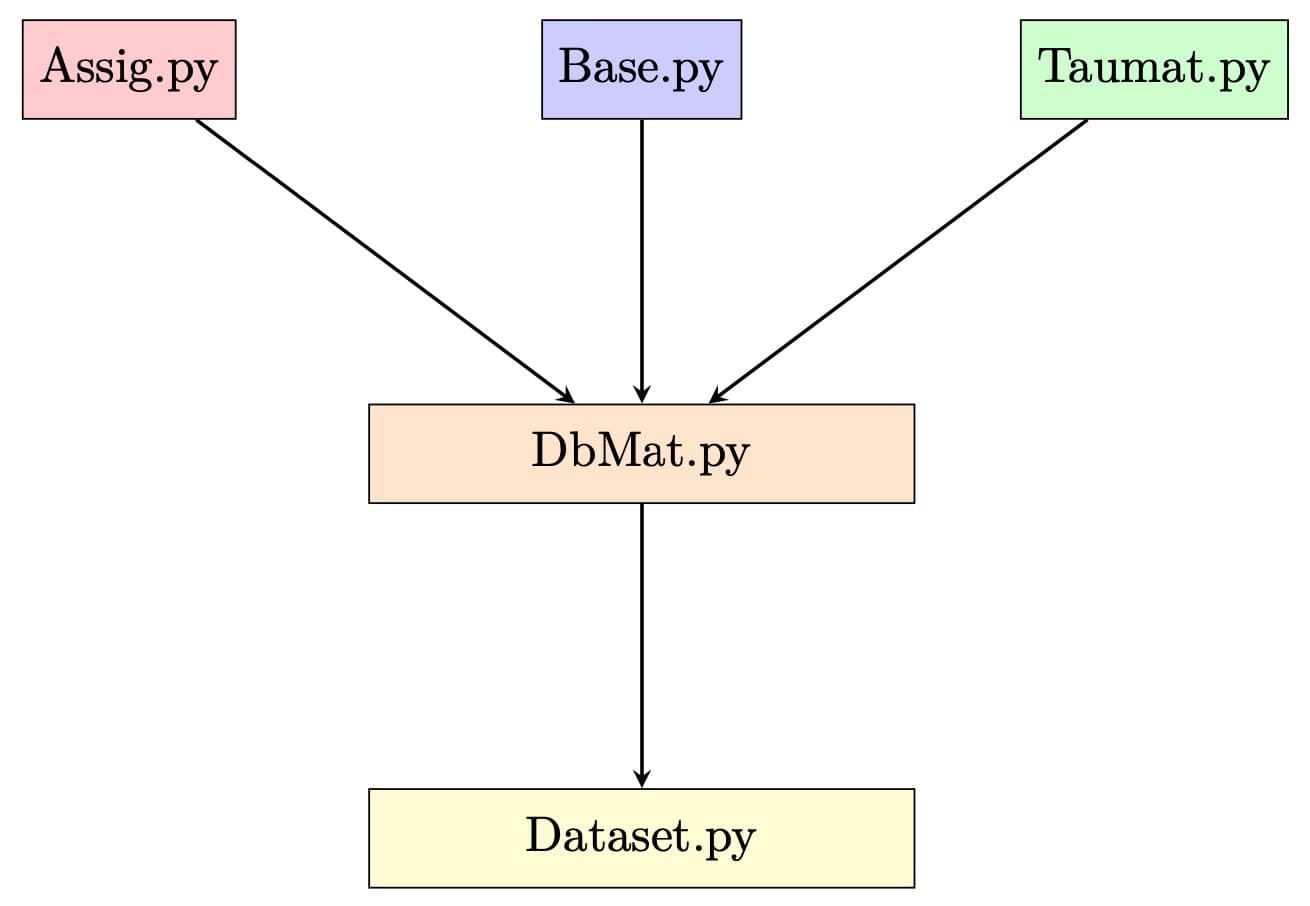
The final transformed dataset filters and resolves common problems with the data such as:
-
Missing data: This occurs when there are no values or data points for a particular sample, which can produce biased results or get inaccurate conclusions. For example, a student that dropped out from the university degree, possibly ending up with no data representing this case. -
Inconsistent data: This occurs when the same data sample is represented differently in different parts of the dataset, making it difficult to analyze and compare. For example, the most simple case it would be the degree format8.75,8,75,8'75, and so on, depending on how the data is managed.
One possible way to transform the dataset is to keep track of the historical evolution of student enrollments. This involves identifying the current point in the student's enrollment history and predicting their future or next enrollment:
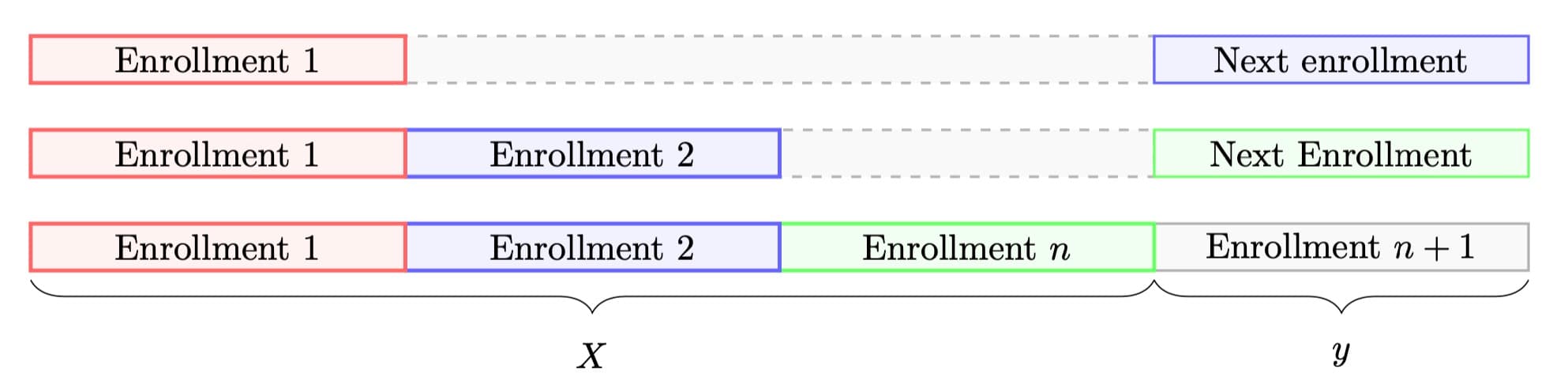
Dataset manipulation
-
Assig.py defines two classes:
- The
Assigclass represents a subject with the following attributes:codi (int): The identifying code of the subject.acro (str): The acronym of the subject.nom (str): The full name of the subject.
- The
PlaEstudisclass represents a set of subjects:_idx_codi (dict): Relates subject codes to instances of theAssigclass._idx_acro (dict): Relates subject acronyms to instances of theAssigclass.
- The
-
Base.py defines the following class:
- The
Quadclass represents a semester in both date and time:q (tuple): A tuple with format(a, q)representing the year of the semester and the time of the semester (fall or spring)
- The
-
Taumat.py defines two classes:
- The
TaulaAcronimsclass represents a table of acronyms for subjects:acro (dict): Relates subject acronyms to their corresponding codes.iacro (dict): Relates subject codes to their corresponding acronyms.
- The
TaulaMatriculesclass represents a table of enrollment data that comes from Prisma, with some basic filters applied:expedients (dict): Contains as keys the student record numbers and as values a list ofMatriculaCrua('expid', 'curs', 'quad', 'assid', 'nota', 'notades', 'tipusnota', 'becat', 'anynaix', 'viaacc', 'ordreass', 'notaacc')corresponding to this record number.cjt_codiass (set): Contains the subject codes of all the enrollments loaded into the table.
- The
-
Dbmat.py is responsible for preprocessing the raw data and building a basic data format that will be used to perform the transformations. In short, it transforms the raw data and exports it to a new base file. Specifically, the following classes are defined:
- The
Matclass represents the enrollment of a subject and the result obtained.assig (Assig): The subject object.nota (float): Obtained grade.notad (str): Description of the grade, for example 'N' (notable), 'NP' (not presented), 'MH' (honors), etc.tipusn (str): Type of grade.
- The
BlkMatclass represents the block of enrollments that are enrolled simultaneously.becat (bool): If the student has a scholarship.lstmat (list[Mat]): The list of enrollments made.
- The
Expedclass represents the complete record of a student.idexp (int): The identifier of the record (anonymized).notae (float): Access grade.viae (str): Access route.ordre (int): Assignment order.anyn (int): Year of birth.mats (dict[Quad, BlkMat]): All the enrollments that the student has made.
- The
BDExpedclass represents the complete record of
- The
-
Dataset.py is the module responsible for defining transformations on the previous preprocessing of the raw data performed by Dbmat.py. Next, the Dataset superclass simply defines the main operations
transformandload_data, where subclasses of Dataset will define their own transformation. This way, we generalize and only these methods will have to be redefined.
class Dataset(object):
def __init__(self, ta: TaulaAcronims, file: str = None) -> None:
self.raw_df = pd.read_csv(file, low_memory=False) if file else None
self.ta = ta
self.dataset = None
def transform(self) -> pd.DataFrame:
"""Applies the data transformation to create and return a dataset"""
raise NotImplemented
def load_data(self) -> Tuple[float, str]:
"""Returns the training data with format (X, y)
"""
raise NotImplemented
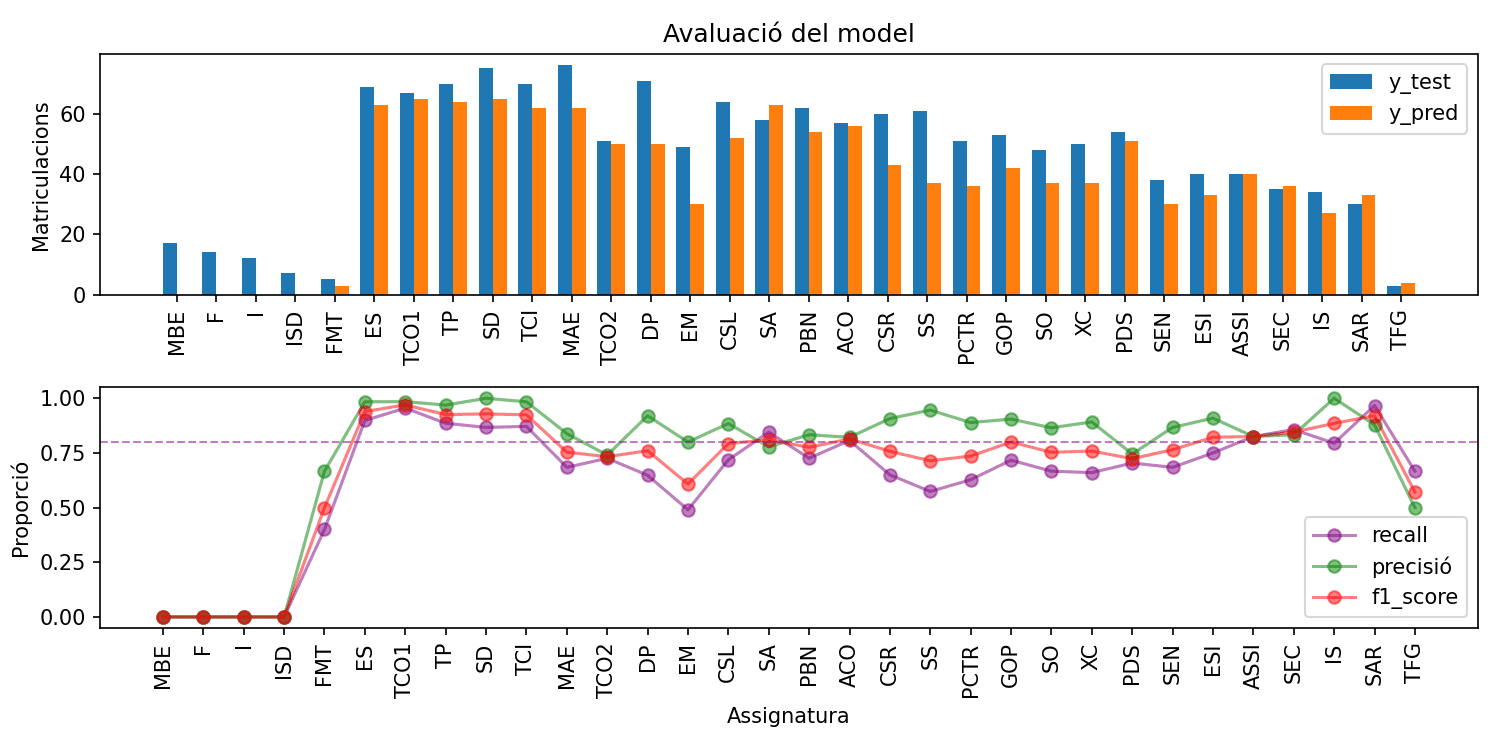
Report
Evaluation
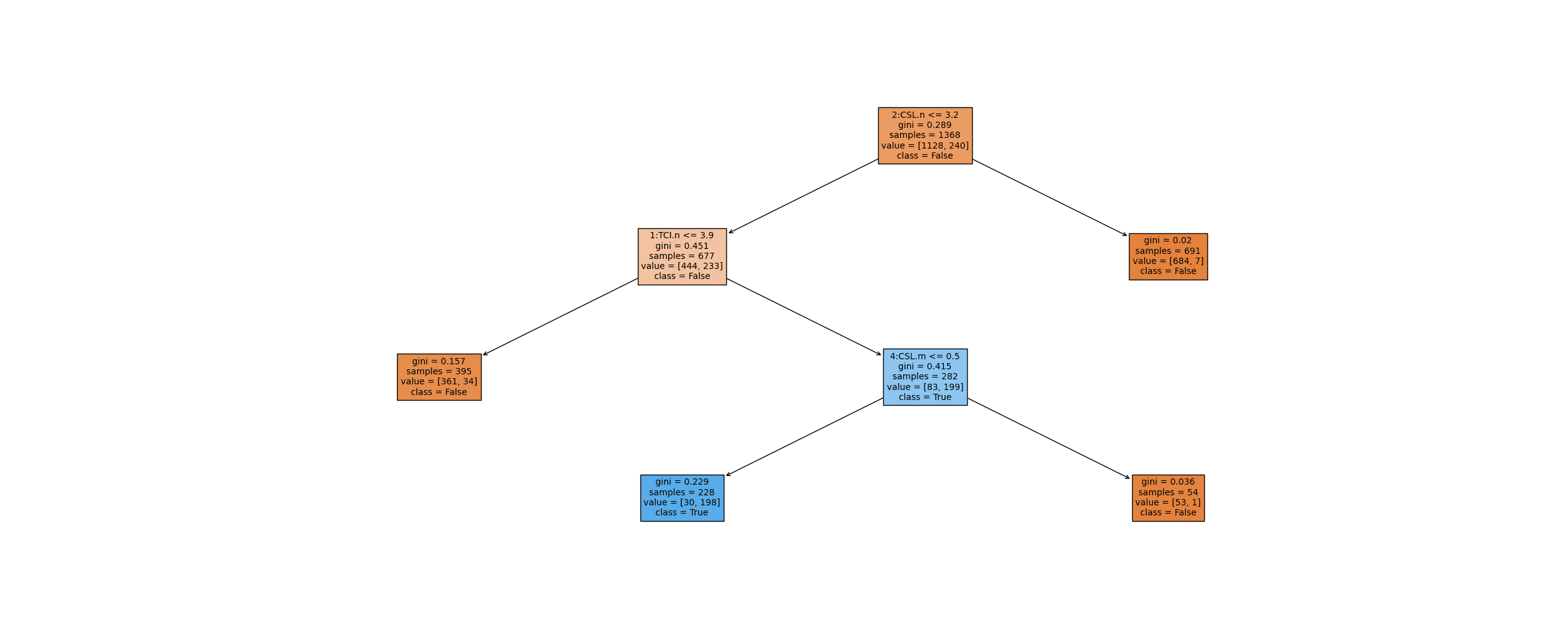
Decision Tree
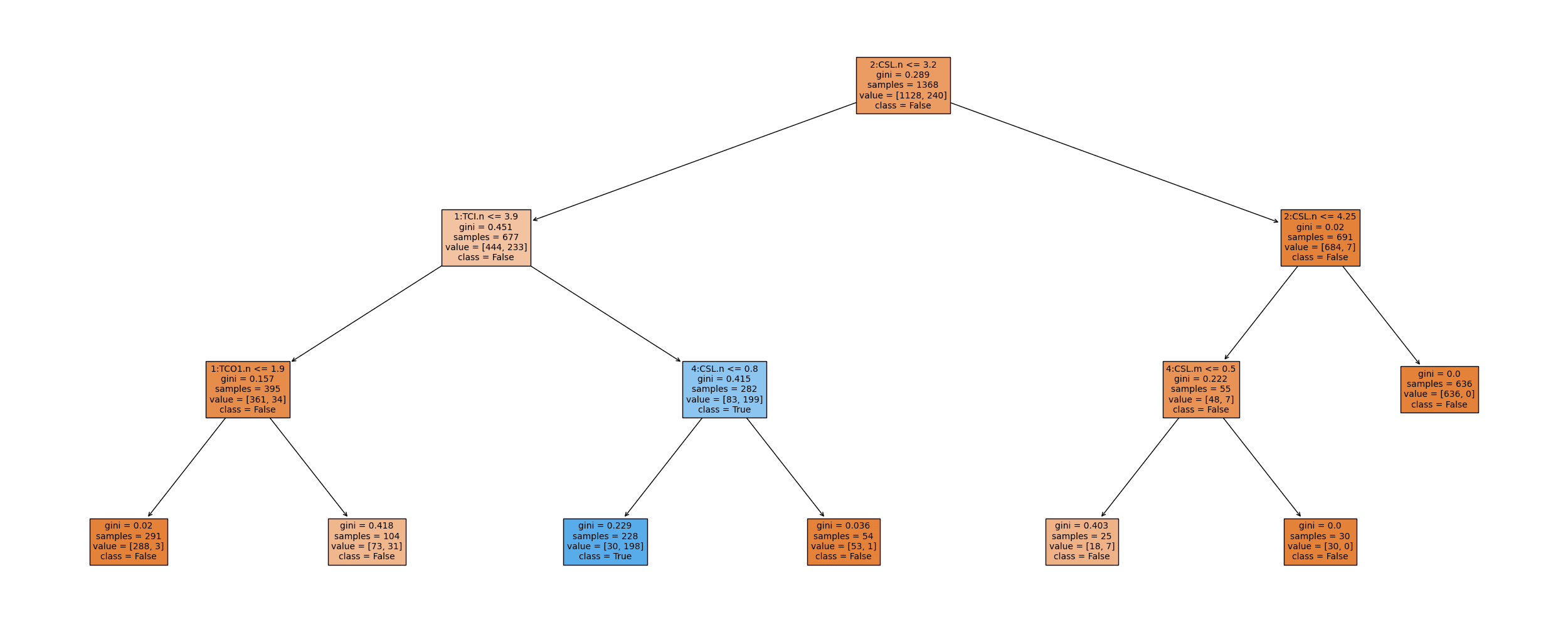
Post-Prunning (CART)
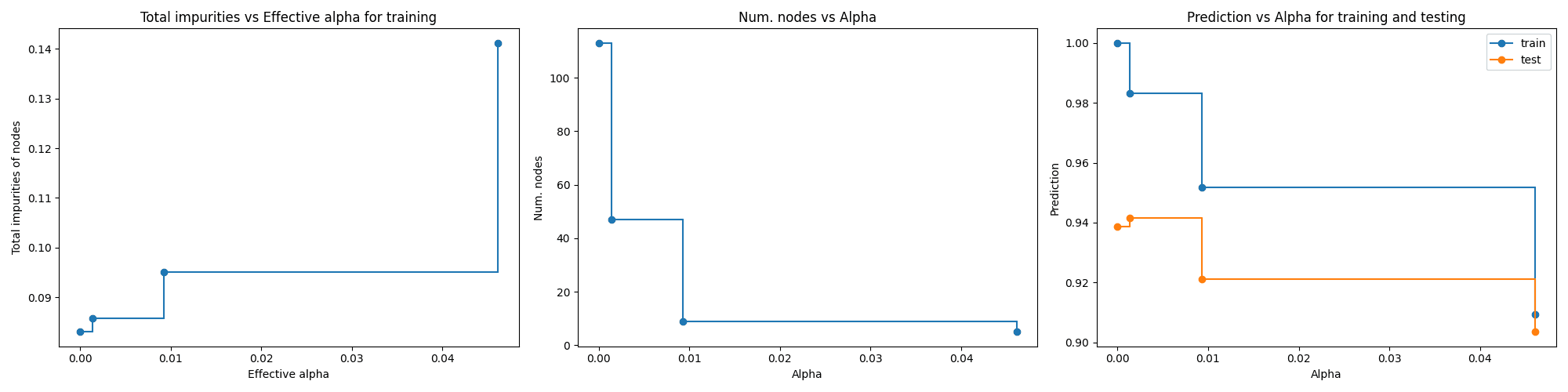
Decision Tree Prunned